Being a software engineer for several years now, I have observed that the performance testing phase of a project is often neglected, sometimes not even considered.
When we develop a new feature, our mind is naturally focused on making it work.
However, this is not enough, and a working feature could quickly become faulty when being used by an unexpected number of users.
What is load testing?
A typical situation you could encounter
Let’s take a basic example: You need to develop a new HTTP endpoint that will take the requester ID as a parameter, and will return information about him (after going through your database or calling others services).
As a first step, you’ll develop the endpoint on your local environment, and test it by calling it once for one user. You’ll see that it’s working well, you’ll decide then to maybe test it on a testing environment with the same scenario and then you’ll release it into production.
Once released in production, you’ll start receiving customers' complaints about how the app is taking too much time to return the information they requested or even worse, the app is simply no longer answering and you now have to solve the issue as an unpredicted emergency.
What led you to this uncomfortable situation?
The problem is that you have tested your feature in a unitary way: one call for one user. But in production, this is not how your endpoint is going to be used: depending on the number of users you have and their activity, your feature is going to be called maybe 10, a 1,000, or a million times in parallel during several hours. How do you know that your code and your infrastructure are ready and adapted to support this amount of requests?
How could this have been prevented?
This is one of the goals of the performance testing (or load testing) phase: while developing your feature, in addition to testing it in a unitary way like you did previously, you’ll also reproduce your production state, to see how the feature behaves when several users are calling it in parallel.
What does the performance testing bring?
It reduces customer frustration.
You’re making sure that the feature you’re releasing will work under heavy load and prevent customers’ complaints about a new feature that is defective
It improves developer experience.
Instead of discovering a performance issue in production once the feature is released and force the developer to fix it quickly and in a stressful context, you can find the same issue before releasing it, and give time to the developer to fix it without having the customer’s frustration as another issue to deal with
It helps product/UX team make relevant decisions when designing the application.
For example, when we need to display a large list of elements, we could do some tests to determine what is the best default number of elements to load at first rendering and then implement pagination, or to answer the question “is a loader necessary?”.
What tool can you use for this?
After some investigations, we’ve decided to choose k6 for the following reasons:
- It's easy to configure and runs on a local environment
- Everything is done via code
- Test could be automatized and integrated to our CI platform (such as CircleCI)
- Testing results could be sent to our monitoring platform (we use Datadog):
- We could correlate these results with the other metrics we’re monitoring
- We could display results in a more understandable way for every stakeholder
- It's open source
There are a lot of other tools on the market, but I didn’t find them as easy to use as K6, this is my personal opinion, feel free to try them to see which one suits you the best:
One big advantage that k6 has over a lot of tools, is the fact that it's scriptable: you could write advanced test scenarios and add external libraries.
Let’s take a concrete use case
At PayFit, we’re handling employees' HR data (contract type, salary, job title, contact information, etc.).
Let’s assume that, without any event-driven approach currently, we want to develop a new feature that will display to an HR administrator all data changes that happened for a specific employee during his time at the company.
The process to find all changes for an employee can be time/resource consuming. For instance, if an employee has been using PayFit for more than 5 years, and if we request to find all changes over this whole time, we’ll have to iterate through more than 60 months of data, and for each month compare a set of values (salary, job title, etc.).
Add to that, the fact that this feature would be used in parallel by several HR administrators of several companies, the final user experience could be very degraded (a lot of time waiting for changes to be displayed or even worse, nothing displayed)
To avoid that, we want to paginate our request: the first time the administrator will be requesting changes, we will be requesting changes that happened over the last X months. On the UI, he’ll have a “Load more” button, if they want to see changes over the next period.
Let’s see how we use K6: With X being a period size in months on which we should detect changes, we want to to find the best X to provide:
- the fastest response to the end user (if we take a too big value for X, we’ll take too much time to detect and return first changes)
- the most fluid experience possible to the end user (if we take a too small value for X, the user will have to click too many times on “Load more” button even to see a small period)
Use case explanation
As an administrator, the first time I land on the employee profile, changes over the last 12 months are requested. If the employee has been present for more than the last 12 months, we add a “Load more” button, so that by clicking on it, we’ll be requesting changes for the next 12 months, and so on.
To determine the number of months we should request each time (12 in the example), we have decided to load-test our endpoint with the following scenario:
- First, we have created a list of fake data containing employees with more than 5 years of existence in the company and put it in a JSON file called “employees.json”
- During 30 seconds, we’ll have 1,000 users that will be executing the following steps in parallel:
- Pick the id of a random employee in the previous list
- Call the endpoint for this employee for a period of X months:
applicationUrl/changes?employeeId=id&startMonth=sm&endMonth=em
- startMonth sm: picked randomly among all the employee’s months
- endMonth em: startMonth + (X-1)
- Wait for 0.25 second
- Restart again from step 1
We’ll run this scenario with X=12, this will give us a first overview of how our endpoint answers when we ask for a period of 12 months. We’ll run it again with X=24, 48, and so on.
Use case implementation
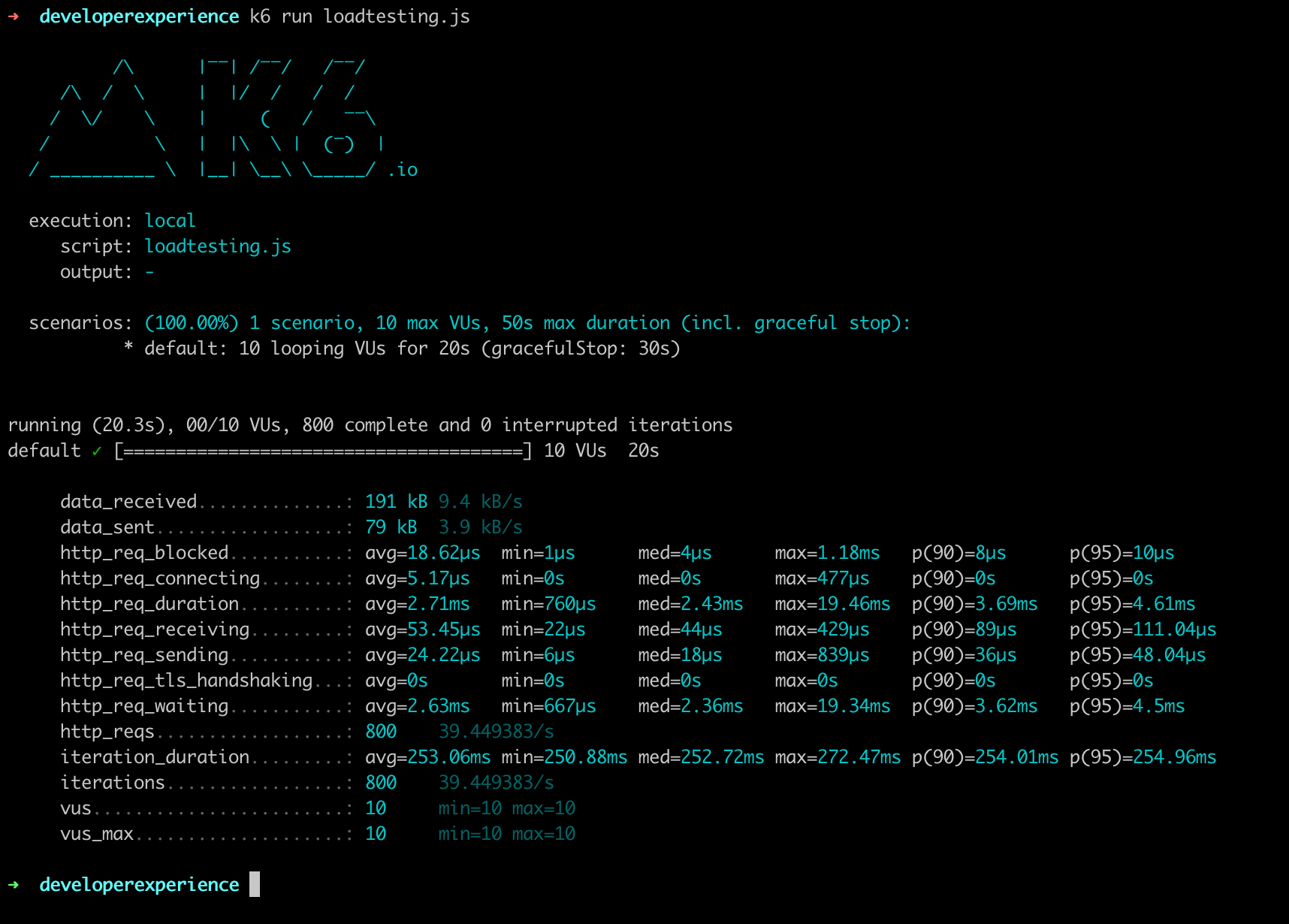
Install k6 on the machine where you want to execute the test, and launch this script:
import http from 'k6/http'
import { SharedArray } from 'k6/data'
export let options = {
vus: 1000,
duration: '30s',
}
// Environment variables
const PERIOD = __ENV.PERIOD
const APP_URL = __ENV.APP_URL
const employees = new SharedArray('employees', function () {
return JSON.parse(open('./employees.json')).employees
})
export default function () {
const employee = getRandomEmployee(employees)
const startMonth = getRandomMonth(employee)
const endMonth = startMonth + (PERIOD - 1)
http.get(
`${APP_URL}/changes?employeeId=${employee._id}&startMonth=${startMonth}&endMonth=${endMonth}`,
)
sleep(0.25)
}
const getRandomEmployee = employees => {
const randomIndex = Math.floor(Math.random() * employees.length)
return employees[randomIndex]
}
const getRandomMonth = employee => {
const randomIndex = Math.floor(Math.random() * employee.months.length)
return employee.months[randomIndex]
}
Let's analyse the script:
- The options object: it defines some basic elements on the way we want to run our test, here we’re telling that we want to have 1 000 users (vus) that will call in parallel and continuously our endpoint, and that during 30 seconds (duration)
- The environment variables:
- The period: the number of months we want to request during our test (12, 24, …)
- The application url on which our endpoint is hosted
- Then we load our employees array, that will be used by every user to select an employee on which he wants to request changes.
- The default function (this is the code executed by one user one time), here he’ll:
- Pick a random employee
- Pick a random month for this employee as the startMonth
- Define the endMonth: it will be calculated thanks to the period we have defined for the test
- Call the endpoint with the previous parameters
- Wait for 1 second and start again
To execute the following script, we run the following command:
PERIOD=12 APP_URL=test.k6.io k6 run script.js
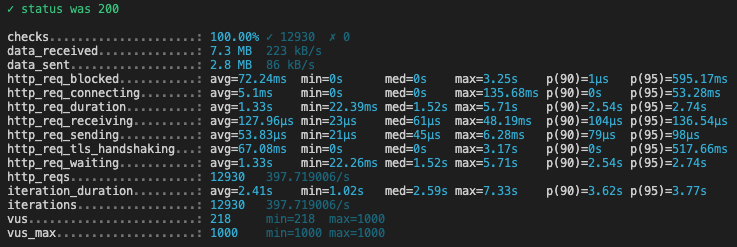
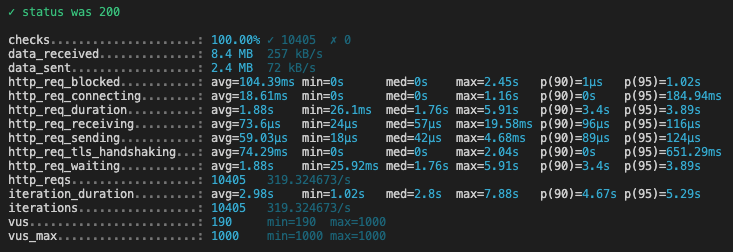
Here are the k6 results for each script execution (we’ve changed the PERIOD each time):
PERIOD = 1
PERIOD = 12
PERIOD = 24
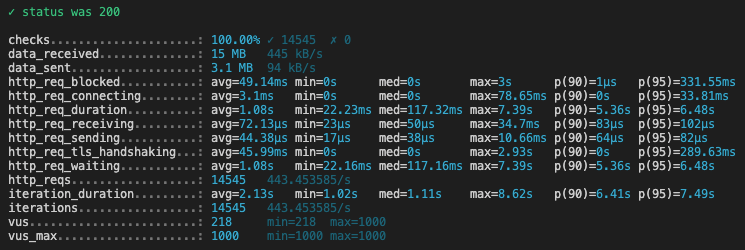
PERIOD = 36
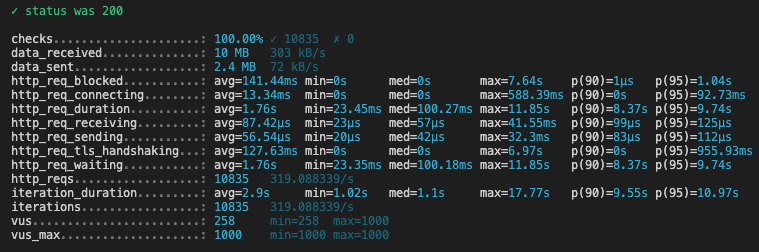
PERIOD = 48
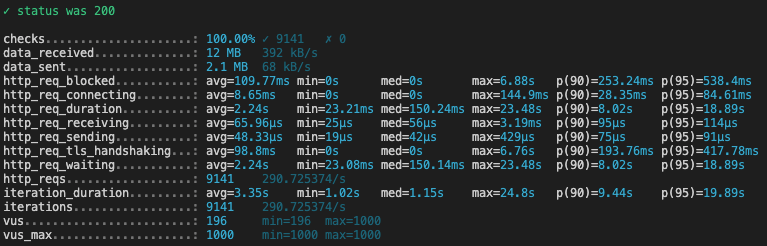
PERIOD = 60
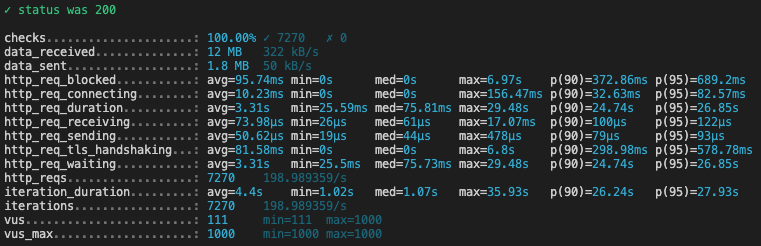
PERIOD = 72
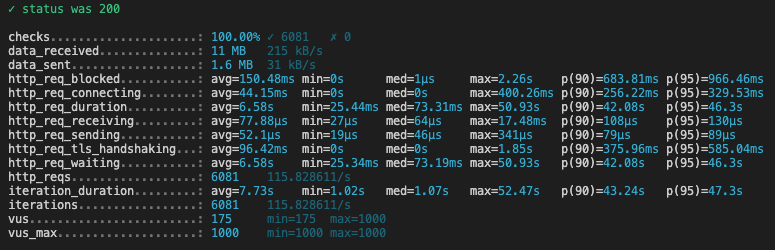
What is interesting to look at in these reports, is the p(90) of the request duration, (ie under how much time are 90% of requests answered to the final client):
| Period (in months) | p(90) (in seconds)* |
|---|---|
| 1 | 2.54 |
| 12 | 3.4 |
| 24 | 5.36 |
| 36 | 8.37 |
| 48 | 8.02 |
| 60 | 24.74 |
| 72 | 42.08 |
These numbers were obtained under extreme conditions, to see how our system behaves in the worst case scenario. Response times in usual production conditions would be smaller.
Use case conclusion
- When we request between 1 and 24 months, 90% of requests are answered in less than 5 seconds
- When we request between 24 and 48 months, 90% of requests are answered in approximately 8 seconds
- After that, request duration increases drastically for 90% of them, we reach 24 seconds for 60 months and even 42 seconds for 72 months
After analysis, depending on the priorities of your team, you could decide to go for a smaller pagination or working on the code or the infrastructure to get a faster response.
Conclusion
Overall, I’m pretty satisfied with my first time experience with k6, I find it really easy to use and the documentation is clear, rich and has a lot of examples. It also brings direct value to the experience we’re building for our customers without having to develop our own tool.
This was just an introduction and one of many possible use cases, we still have a lot of possibilities to explore and that are already planned in our roadmap:
- Integrate k6 to our CI, to be notified for example if a commit introduces a performance regression
- Create dashboards to analyse in real time the performance of our application in production
Header photo by 713 Avenue.


