Since the beginning of PayFit, we have relied on MongoDB to store and manage our data. After more than 2 years, we eventually decided to shard our single replica set into several sharded replica sets to cope with our exponentially growing dataset.
Let’s remind ourselves how MongoDB manages sharding. You’ll find 3 types of instances:
- one or more
mongos, that act as a router for all the queries - a single
csrs(Config Server Replica Set) that stores the sharding configuration - one or more
shardreplica sets, that store all the data
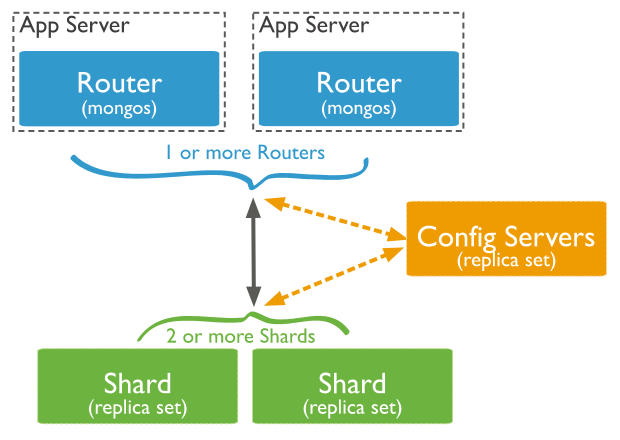
When one performs a query, it first heads to one of the mongos instances, which then talks with the csrs instance to get the shard mapping. It then routes the query to the right shard/shards instance(s) (but we should also remember that the mongos instance can also cache the configuration and bypass the csrs instance).
It is also important to point out that the csrs and the shard/shards instances might also be made of :
- 1 primary leader after election, that can handle read/writes
- 1 or more secondaries for replication, that can only optionally handle read operations
Sharding makes it possible for us to scale our database horizontally (along with the size of our dataset). Using replica sets for each of our shards makes our cluster highly available: a single node/zone failure results in no downtime, and — most of the time — we can perform maintenance operations during the day, without taking our app offline”.
Setting up backups to prevent data loss
Everyone knows the importance of creating backups of your data. What it even more important is how you tune your backup strategy so that it fits your needs.
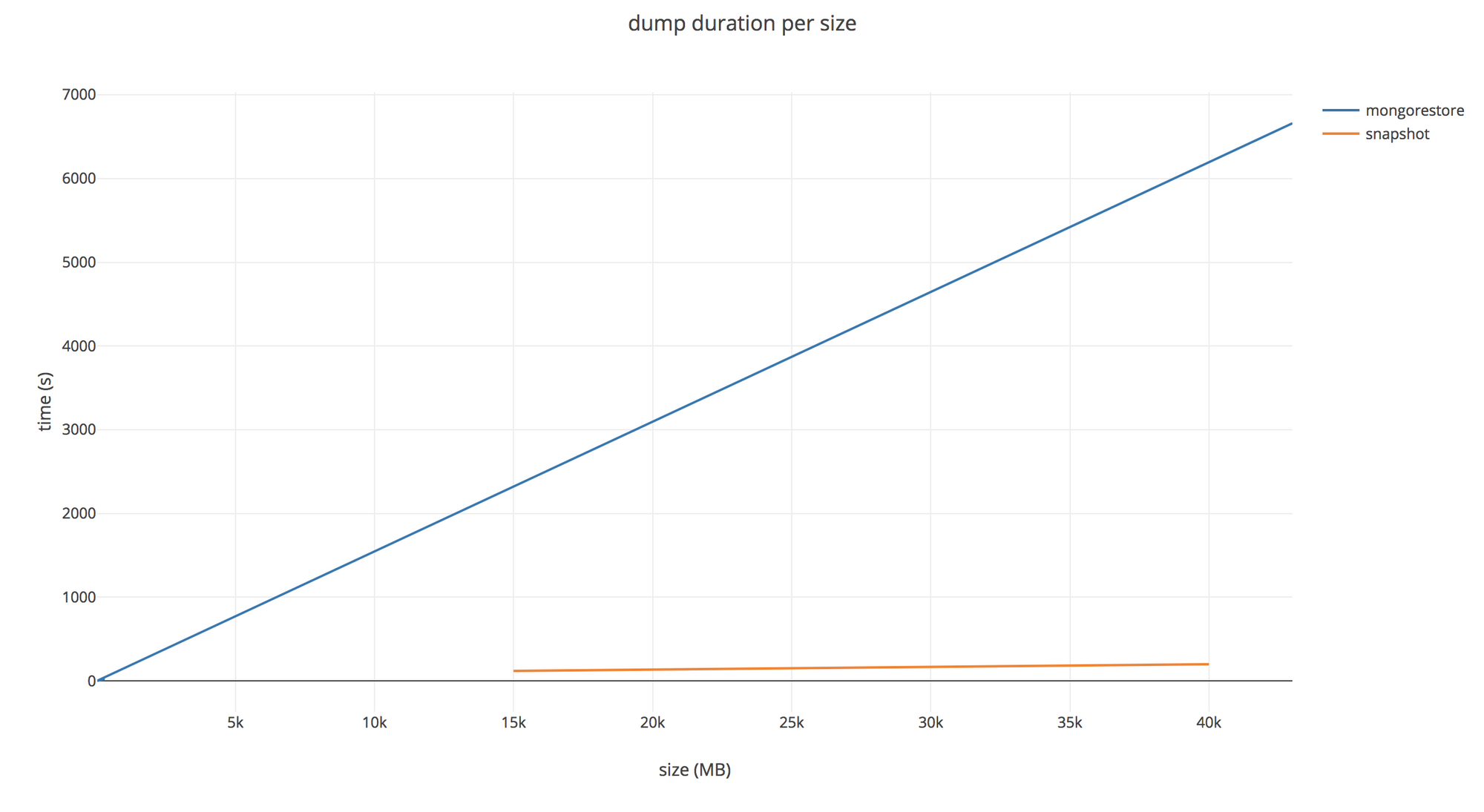
Mongo provides us the de facto tools to perform dumping/restoration operations on our database. The tools come in the form of the CLI commands: mongodump and mongorestore. They are great tools, and we won’t discuss their legitimacy here. Both of them do the job when it comes to creating backups or restoring them onto an existing database. But sadly, we realized this solution was not as scalable as we had hoped.
As we can see here, the bigger the database becomes, the longer the mongodump operation will take. That’s easy to understand. Moreover, your production database might suffer some overhead if you need to perform this operation once every hour (for example).
We’ve been thinking a lot about how to reduce the load, as well as the duration, of the operation. Currently, our Mongo cluster is being hosted at AWS with EBS volumes storing our data. And the good news is: EBS comes with a built in snapshotting API.. Snapshotting all our single volumes allows us to keep track of all our data in an almost instant way — note that the initial snapshot might take a long time to be created. Moreover, one might notice that snapshotting a volume only refers to performing a diff between a previous saved state and the new one. So, instead of having terabytes of backups, you only need to write a few gigabytes of diffs every time you backup.
Since EBS creates point in time snapshots leveraging a copy-on-write-mechanism, we can fsynclock our mongo instances, trigger all snapshots, fsyncunlock them in just a few dozens of milliseconds. The impact on performance is unnoticeable to the end-user and our snapshots’ consistency is guaranteed.
Let’s say now that we have the following configuration (omitting our mongos instance since they store no data):
- 1
csrs, made of 1primaryunit and 2secondaries - 2
shards, made of 1primaryunit and 2secondariesas well
After the backing up of our data is done, we will have:
- 3 snapshots for the
csrsinstance - 6 snapshots for our
shardsinstances, with half of them storing the same data
In a scope where backups are only used to purely restore data, we now need a way to perform this operation from EBS snapshots.
Restoration made blazing fast
There is sadly no option for mongorestore to handle EBS snapshots out of the box. We want to make things fast, but we need to define what fast means to us.
We would like to be able to take all these snapshots, put them back on live volumes, plug these volumes into some containers running the appropriate process to handle that very said data, and then talk to them as if they were still running in production. Luckily, Kubernetes makes all that possible without too much pain.
We will not discuss the way Kubernetes works here, but if you’re not familiar with it, take a look at the official documentation. Anyway, you can easily reproduce all of the steps using different tools like Consul, OpenStack, or even the AWS SDK. We will assume that you already have a running cluster inside which you can create whatever you want.
Creating common resources
Prerequisites
Before starting, we’ll assume we already have created a mongo-restore namespace to play around with our stuff. Also, since every replica set is made of a primary and 2 secondaries(secondaries can only replicate the primary one, so we can ignore them). We only need to restore the 3 primary volumes, one for each replica set.
Here is a table of the requirements for each type of instance:

We will use <volume-id> of the EBS volume as a generic unique identifier in the following manifests but this value is intended to be formatted better for names and labels (e.g. mongo-config, mongos, shard-0, shard-1…).
Common resources manifests
Let’s start with the resources definitions we need. All of the non static definitions will be written in the Go language. Here we create an EBS volume from a snapshot:
As you can see we create a new EC2 volume with type io1 and iops capability of 50 times the size of the volume (which is the maximum AWS allows). We will need this to ensure that the indexing of the database on startup is performant. We’ve actually noticed that after restarting the shards, it took a look time for the global cluster to become available and it seemed to be because mongo was trying to recreate its state from the oplog. Setting these values drastically reduced this time. Here we create a Persistent Volume to store our data:
Setting nouuid as a mount parameter is mandatory to avoid UUID duplication in case multiple snapshots of the same disks are restored and mounted on the same EC2 instance. Otherwise you probably won’t be able to mount the volume. Here we create a Persistent Volume Claim for each PersistentVolume to attach them into Pods:
Here we create a headless service:
Spin up the instances
Setting up the Mongo configuration
Each type of instance will require a different startup command. But for our mongo config, we will share the same ConfigMap across all the pods. This configuration is very standard and can be fine tuned as much as you need. As far as I know, there are no specific requirements. Here is a mongo instance configuration file:
Creating the pods
Before getting started with the manifests, we need to be wary of one subtle point. When you start the Mongo Docker image, the user:usergroup default value is 999:999. In our case, our /dta/db folder that holds the data on our volumes did not belong to this user. This is why we needed both the csrs and shards instances to set an initContainer which is in charge of changing the permissions recursively to allow the 999 user to read/write it. You’ll notice it in all manifests.
Starting with the csrs instance, we require running the mongod command with the configsvr flag to inform mongo about the role to play. We will tell it to listen on port 27019. We also setup a readinessProbe to ensure mongod started correctly and that the rs configuration is available before provisioning it.
For each shard, we start mongod with the replSet flag set to the right shard-x value. We need to be sure that this value is the same as the one of the original shard running in production. Otherwise, it will not start up. You can get the shard running by launching the command use config; rs.conf() on each shard.
We define the same readinessProbe as for the csrs. After provisioning our shards, we will need to restart them while adding a shardsvr flag to the startup command.
Provisioning our instances
All the following golang code is using globalsign/mgo (be aware the original repository of mgois not maintained anymore). Using the official mongo driver might also be a great option.
First, we need to configure our csrs to inform it that there is only one instance in the replica set instead of 3, and we need to advertise its local address.
Then, we also need to configure our shards for the same purpose and add the csrs host to the configuration of our replica set.
When we are done with it, we can restart our shards and add the shardsvr flag to the startup command. This time, each primary instance of each shard will act as a ready to use replica set. It might take a long time for the shards to be up and running. It’s now time to advertise the hosts of all our shards to the csrs.
We are finally ready to create our mongos instance to talk with our sharded mongo cluster:
We’ve now setup everything we needed. You can try to talk to your sharded mongo by running kubectl -n mongo-restore port-forward mongo-config 27017:27017 and then running mongo on your local machine.
Automating this process now allow us to restore data onto our production cluster in less than 7 minutes against 45 minutes a few months ago.
Cleaning up your workspace
I’ve voluntary added annotation to every single instance so it’s quite easy to get rid of them:
Conclusion
We’ve finally managed to setup a fast and reliable configuration to spin up a sharded MongoDB cluster atop Kubernetes easily. We are now using this process on a daily basis at PayFit to restore data in record time for all our customers. We know that there are still probably a lot of ways to improve the performance.
Thoughts? Questions? Suggestions? Don’t hesitate to leave us a comment.
Thank you for reading 🚀
A warm thank to Andrew Kowalczyk for his help to correct my English and Etienne Lafarge for his precious advice
-- Elliot Maincourt, SRE @Payfit.

