At PayFit, we believe in using tools that improve the developer experience of our ICs, favoring technologies that reduce time to deliver new features or bugfixes, and not get bogged down in configuration and setup intricacies.
On the other hand, we hold ourselves to high engineering standards and expect ICs to enforce as many engineering principles and best practices, in order to prevent avoidable problems and minimize technical debt, contributing to our goal of keeping a high velocity.
Unfortunately, using high-level tools sometimes obscures the details behind a technology, and makes it harder to identify and apply best practices. In this context, our team recently went on an investigation, and emerged with a recommendation that you might find useful too.
Context
The service we were working on is a Node.js API server, written in TypeScript, using the following data stack:
- Amazon Aurora with PostgreSQL 14.5 compatibility
- Prisma Migrate for schema definition and migrations
- Prisma Client as ORM and database client
Indexing Foreign Keys in PostgreSQL
Here’s what the PostgreSQL documentation has to say about indexes on referencing columns for foreign keys:
A foreign key must reference columns that either are a primary key or form a unique constraint. This means that the referenced columns always have an index (the one underlying the primary key or unique constraint); so checks on whether a referencing row has a match will be efficient.
Since aDELETEof a row from the referenced table or anUPDATEof a referenced column will require a scan of the referencing table for rows matching the old value, it is often a good idea to index the referencing columns too.
Because this is not always needed, and there are many choices available on how to index, declaration of a foreign key constraint does not automatically create an index on the referencing columns.
Prisma schema migrations for relations
For the following data schema, defined in Prisma’s DDL, containing a 1:N relation between Foo and Bar:
model Foo {
id Int @id @default(autoincrement())
name String
bars Bar[]
}
model Bar {
id Int @id @default(autoincrement())
label String
fooId Int
foo Foo @relation(fields: [fooId], references: [id], onDelete: Cascade)
}Prisma Migrate generates the following migration in SQL:
-- CreateTable
CREATE TABLE "Foo" (
"id" SERIAL NOT NULL,
"name" TEXT NOT NULL,
CONSTRAINT "Foo_pkey" PRIMARY KEY ("id")
);
-- CreateTable
CREATE TABLE "Bar" (
"id" SERIAL NOT NULL,
"label" TEXT NOT NULL,
"fooId" INTEGER NOT NULL,
CONSTRAINT "Bar_pkey" PRIMARY KEY ("id")
);
-- AddForeignKey
ALTER TABLE "Bar"
ADD CONSTRAINT "Bar_fooId_fkey"
FOREIGN KEY ("fooId") REFERENCES "Foo"("id")
ON DELETE CASCADE
ON UPDATE CASCADE;Prisma queries for relations
When performing a query on a relation, Prisma does not use JOIN s.
For example, this code:
client.foo.findMany({ include: { bars: true } });produces the following queries:
SELECT "Foo"."id", "Foo"."name"
FROM "Foo"
WHERE 1=1;
SELECT "Bar"."id", "Bar"."label", "Bar"."fooId"
FROM "Bar"
WHERE "Bar"."fooId" IN ($1,$2);Running a benchmark
In order to compare performance of indexed and non-indexed foreign keys, we decided to run a benchmark on a number of operations ( INSERT, SELECT, DELETE...).
Data model
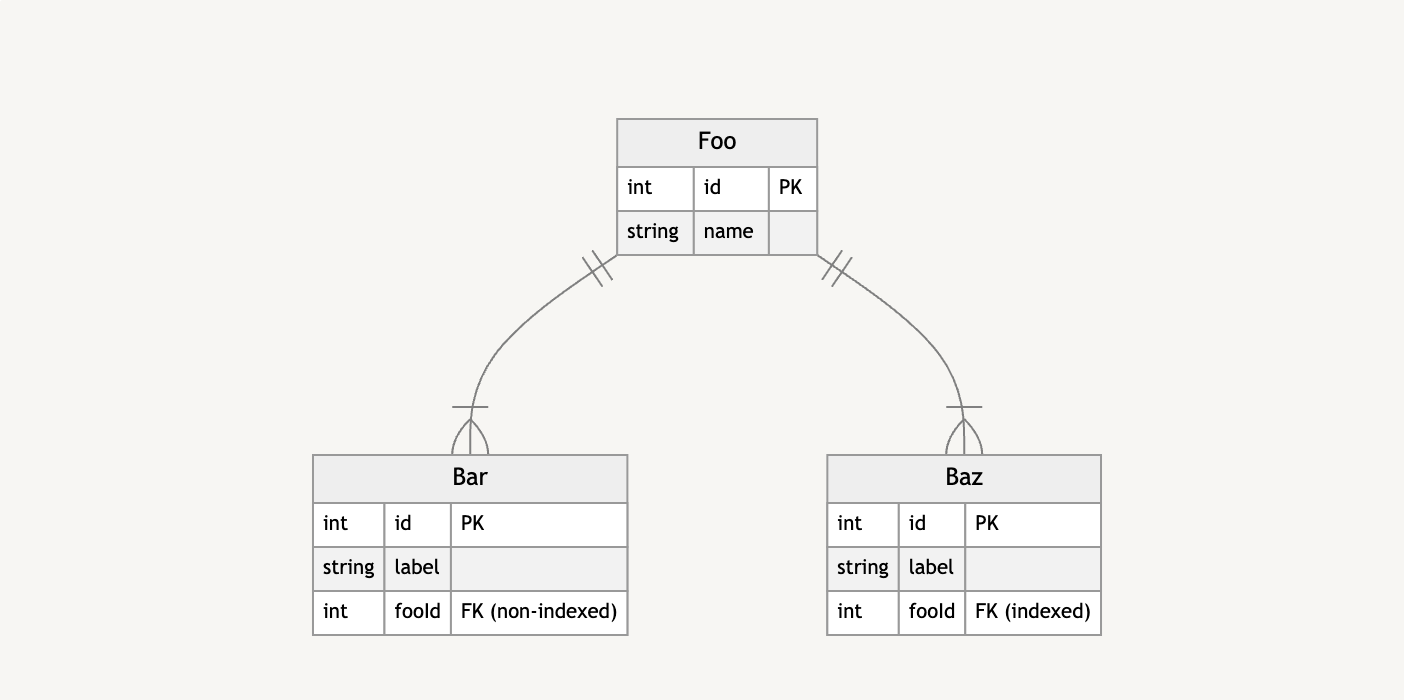
The benchmark uses the following schema:
model Foo {
id Int @id @default(autoincrement())
name String
bars Bar[]
bazs Baz[]
}
model Bar {
id Int @id @default(autoincrement())
label String
fooId Int
foo Foo @relation(fields: [fooId], references: [id], onDelete: Cascade)
}
model Baz {
id Int @id @default(autoincrement())
label String
fooId Int
foo Foo @relation(fields: [fooId], references: [id], onDelete: Cascade)
@@index([fooId])
}
Synopsis
The benchmark runs the following steps:
- Create M Foos
- Create N Bars, linked to random Foo
- Read all Foos with linked Bars
- Update all Bars, relinking to a random Foo
- Delete N/2 Bars
- Delete all Foos, cascading deletes into linked Bars
The benchmark then runs again for Bazs.
Benchmark runner specs
- AWS EC2
t2.microinstance - Ubuntu 22.04
- Node 18.13.0
- Prisma 4.8.0
- Amazon RDS PostgreSQL 14.5 on
db.t4g.micro
The benchmark runs for:
- 10 Foos
- 10,000 Bars/Bazs
The benchmark is run 50 times.
Benchmark results
Unindexed
| Operation | Min time | Avg time | Max time |
|---|---|---|---|
| 2. Create | 384ms | 490ms | 890ms |
| 3. Read | 66ms | 73ms | 261ms |
| 4. Update | 14953ms | 15288ms | 16248ms |
| 5. Delete | 149ms | 188ms | 274ms |
| 6. Cascade | 15ms | 21ms | 32ms |
Indexed
| Operation | Min time | Avg time | Max time |
|---|---|---|---|
| 2. Create | 404ms | 515ms | 1037ms |
| 3. Read | 53ms | 57ms | 72ms |
| 4. Update | 15032ms | 15365ms | 15804ms |
| 5. Delete | 152ms | 197ms | 500ms |
| 6. Cascade | 15ms | 22ms | 95ms |
Performance
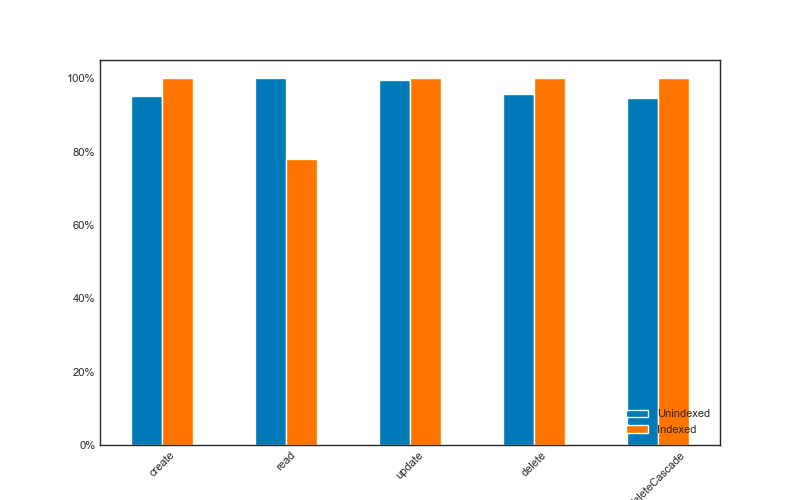
| Operation | Indexed / Unindexed |
|---|---|
| 2. Create | 105% |
| 3. Read | 78% |
| 4. Update | 101% |
| 5. Delete | 104% |
| 6. Cascade | 106% |
Conclusion
Observations
The benchmark shows us that create, update, and delete are slightly faster when the referencing column is unindexed, whereas read is significantly faster when indexed.
More generally, we can say that indexing improves reads but slows down writes.
This could be expected, as every write of an indexed column will need re-indexing, and every read with a clause on an unindexed column will require a full-table scan.
Lessons learned
To the question “Is it good practice to add an index to your referencing columns (foreign keys)?” we can answer with a general “yes”.
For a more fine-grained answer, we can say… it depends. It depends mostly on your access patterns.
Typical application data models will have a high read-to-write ratio, meaning that data is read more often than it is written. Examples of these types of data include textbook cases like company/employee relations, or listing all posts from a given user for a blog.
On the other hand, some data models will have a higher write-to-read ratio. Analytics, monitoring and IoT sensor data fall into this category, as new data is ingested into the system on a recurring basis, whereas reading the data is less frequent, often to perform overall analysis and reporting.
If your data seems to respond to the latter case, perhaps the overhead of indexing data could be a cost you wish to avoid. It might even be worth looking into OLAP and time-series databases, such as InfluxDB or Clickhouse.
Appendices
Source code
The code for the benchmark is available on GitHub.
Prisma SQL
For each step, Prisma generates the following SQL queries
1. Create M Foos
INSERT INTO "Foo" ("name") VALUES ($1), ($2)...
2. Create N Bars, linked to random Foo
INSERT INTO "Bar" ("fooId","label") VALUES ($1,$2), ($3,$4)...
3. Read all Foos with linked Bars
SELECT "Foo"."id", "Foo"."name" FROM "Foo" WHERE 1=1
SELECT "Bar"."id", "Bar"."label", "Bar"."fooId"
FROM "Bar"
WHERE "Bar"."fooId" IN ($1,$2...)
4. Update all Bars, relinking to a random Foo
UPDATE "Bar"
SET "fooId" = $1
WHERE ("Bar"."id" IN ($2) AND ("Bar"."id" = $3 AND 1=1))
5. Delete N/2 Bars
DELETE FROM "Bar" WHERE ("Bar"."id" IN ($1,$2...))
6. Delete all Foos, cascading deletes into linked Bars
DELETE FROM "Foo"
WHERE ("Foo"."id" IN ($1) AND ("Foo"."id" = $2 AND 1=1))
Header picture by Bisakha Datta / Unsplash

